CBR Workshop @ IJCAI'99
| On the 2nd. of August there was a workshop called "Automating the Construction of Case-Based Reasoners" organised by Sarabjot Singh Anand, Agnar Aamodt and David Aha. The workshop featured 13 paper presentations and some time for participants to discuss issues and themes - obviously it was a very full day. As usual if you presented a paper at the workshop and your paper or presentation is available online I'd be grateful if you could email me the URL. This will make this report much more useful to people. |  |
| The workshop opened with the first of two invited talks by Ralph Bergmann who (briefly) described the INRECA methodology. Ralph identified 3 types of CBR: textual, conversational and structural (these would map to the tools: CBR-Answers, k-commerce & CBR-Works). Ralph primarily is interested in structural CBR, i.e., where there is an underlying domain model in addition to case data. INRECA is a methodology, with tool support, based upon the experience factory approach and software process modelling. It's no surprise that INRECA encourages the reuse of past CBR project experience. Ralph reported a reduction in planning and development time by a factor of 10 when project plans and models are reused from one CBR project to the next. |
|
| An excellent new book (with a CD-ROM of tools) describing the INRECA
methodology has just been published. It can be ordered online from amazon.com:
Developing Industrial Case-Based
Reasoning Applications : The INRECA Methodology |
|
David Wilson presented a paper called: On
Constructing the Right Sort of CBR Implementation. This work presented a simple
framework of "task-based" systems optimised to a single task; "enterprise
systems" that are integrated with business processes and link to relational databases
and "web-based" systems that are distributed and use XML as an application
independent exchange medium. Obviously these categories are not exclusive but David did
describes ways of mapping from one to another. Two challenges to the community arose from
this:
Download this paper (pdf format) or visit the project website (this includes a Java demo of the system). On a personal note, David is finishing his doctorate soon (well in the foreseeable future) and will be looking for a highly paid job. Send all offers to davwils@cs.indiana.edu |
|
| Margaret Richardson presented a paper called: A systematic ML approach to case-matching in the development of CBR systems. Much as the title suggest this presented a systematic and thorough evaluation of case-matching (i.e., similarity and retrieval methods). A 9 level framework was presented from random (i.e., just select any case) to increasingly more complex (and hopefully) more accurate methods. This was tested using a range of datasets from the UCI repository. As has been mentioned before, the problem with the UCI data sets is that they are classification data. Not all CBR systems operate in classification domains, and certainly few operate as binary classifiers. However, this was an interesting paper and well presented. |
|
We then had a discussion led by Agnar Aamodt and
Barry Smyth on "how automated can we make the construction of CBR systems"?
Barry suggested that the following tasks can be automated (or at least supported):
What could not be automated (and was poorly supported) was:
The discussion that followed recognised that the set of "can't do's" all refer to case construction, whereas the set of "can do's" all refer to case-base maintenance activities. Thus, the conclusion could be drawn that CBR construction can't be automated by CBR maintenance might be. |
|
| Helge Langseth presented a paper called Learning
Retrieval Knowledge from Data. This work from the Norwegian CBR group at Trondheim
was one of several papers presented at the workshop. They use a knowledge intensive
case-representation based on the Creek knowledge representation. Bayesian Networks are
used to learn causality from the Creek networks and case-data. At the heart of this was
the message "learn what you can from the data and augment this with human
knowledge". Download the paper (postscript). |
|
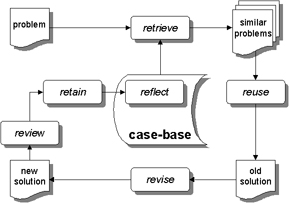
| Frode Sormo (also from Trondheim) discussed the issues of keeping the knowledge base updated in knowledge intensive case-based reasoners in a paper called Knowledge Elaboration for Improved CBR. They've identified a possible 6th RE in the CBR-cycle, namely "reflection", being introspective processes that a CBR system might use to improve or maintain its performance when a new case is retained. They also identify the "boot-strapping" problem which arose from the earlier discussion. Namely, that automated techniques only work once a sufficiently representative case-base exists. | |
| Barry Smyth then presented a paper called Constructing Competent Case-Based Reasoners: Theories, Tools & Techniques that summarised the work that he and his group have been involved in for the last 4 years. He now believes that competence models (the core of his research) can guide retrieval, adaptation, maintenance and authoring. The competence model and its different uses were described and Barry ended by showing some tantalising screen shots of a tool called CASCADE that supports case-base authoring using the competence model - watch this space. | |
| Ture Friese presented another paper from the Trondheim group combining Creek with Bayesian Belief Networks (BBNs). Ture uses BBNs to support a CBR problem solver where the BBN can calculate arc weights in the Creek network that can be used to provide causal explanation when a case is retrieved. |
|
| Ole Martin Winnem presented a fascinating system for Applying CBR and Neural Networks to Noise Planning for the Norwegian artillery. Predicting how noise will travel is a complex problem and again knowledge intensive case-based reasoning plays a crucial part. The benefit of using CBR is the automatic reference to past experiences that the user gets for justifying decisions. |
|
| David McSherry presented a paper called Relaxing the Similarity Criteria in Adaptation Knowledge Discovery. There are similarities to the work being done by Barry Smyth here in that this deals with coverage of the problem space. David's system, called CREST, discovers adaptation knowledge through an algorithm called disCover that discovers all cases that can be solved within the CREST case-library. The system operates in a numeric estimating domain and basically offline it can identify cases that don't exist but can be solved. These can then be generated so no adaptation is required at run-time, only retrieval. |
|
| Juan Corchado presented a Descriptive rules model for learning and pruning the memory of CBR systems. This technique creates a binary tree to index cases based on interval factors. Cases that are no longer needed are can be pruned by the rules extracted from the tree. This technique was illustrated in a real-time forecasting domain and showed that case-base size could be maintained to logarithmic growth. |
|
| Paulo Gomez showed that it is possible to Convert Programs into cases for Software Reuse. Paulo system can automatically convert software programs into cases described at both a functional and behavioural level. This enable a programmer to retrieve software code based either on the function or the behaviour desired. It is not surprising however that it is possible to transform one well formed representation into another using rules. It would be more interesting if these rules could be automatically learned. |
|
| Jacek Jarmulak uses Genetic Algorithms for feature subset selection and weighting. What I found interesting here was that using GAs to identify feature sets and adjust weights did not improve much on a standard C4.5 algorithm. For a standard k-NN algorithm GAs learning the feature weights improved performance by about 15%. Overall this shows (again) how robust the basic C4.5 and k-NN algorithms are. |
|
| Illesh Dattani described a system for Case-based Maintenance through Induction. This supports the creation of hybrid systems that can construct cases from raw data (such as maintenance logs) as well as revise and refine existing case-bases. It was easier to see how the revision and refinement would work. Automatic case-base construction would depend on clean well represented data - which in practice is rarely the case. |
|
Overall commentsThe workshop presented a wide range of case-based systems from the knowledge intensive systems using the Creek representation to knowledge poor systems such as those of David McSherry's and Illesh Dattani's. In the later examples, induction and introspection can lead to case creation. In the former knowledge engineering is always needed. However, methodologies, such as INRECA, can reduce the effort required by encouraging the reuse of past system building experience. It is clear that a wide range of maintenance activities can be semi-automated and in well understood domains even totally automated. However this is rarely so for case-base construction. It is also clear now that our understanding of the CBR process has increased with time. |
|













Many people now recognise that there are more than
four processes in the CBR-cycle and this workshop definitely makes a strong case for a
6th. process involving introspective reflection after a new case is retained.
|
 |
[Home] [CBR Sessions]
![]()